Migrating to Kubernetes with zero downtime: the why and how
Originally posted on the Manifold blog

We at Manifold always strive to get the most out of everything we do. For this reason, we continuously evaluate what we’ve done to see if it still holds up to our standards. A while back, we decided to take a deeper look at our infrastructure setup.
In this blog post, we’ll look at the reasons why we moved to Kubernetes and the questions we asked ourselves. We’ll then look at some of the compromises we had to make and why we had to make them. We’ll also have a look how we configured our cluster to achieve our goals.
When we started Manifold, we did what we knew worked well. Use Terraform to deploy containers on AWS EC2 and expose these through ELBs. We found ourselves in a position where we could spend some extra time on building a more mature platform. The initial implementation was very simple to begin with, but we started to see some pain points:
-
Deploying was slow (~15min)
-
No Continuous Delivery meant only the Ops people knew how to deploy
-
Running a single container per instance can become expensive. By increasing container density, we could decrease cost
In the past year, Kubernetes has become very popular. With the experience the team had, we strongly believed in the future of this new technology. For this reason, we created our first Kubernetes Integration. We also started thinking about integrations which would make Kubernetes more accessible. This is where the idea of building Heighliner was born.
This leads us to another principle we live by: dogfooding. By using Manifold to build Manifold, we’d know exactly what our users need.
Choosing a cluster
The first question we asked ourselves was “where are we going to run this cluster?”. AWS does not offer a Kubernetes solution yet but Azure and Google Cloud Platform do. Do we need to stay within AWS and manage our own cluster or do we want to move everything to another Cloud Provider?
The key questions we wanted answers to were:
-
Can we create a High Availability cluster on AWS and how easy is it to manage this?
-
How do we connect to our RDS instance and what will the latency be?
-
What do we do about our KMS encryption?
High Availability (HA) with kops
If we can easily create and manage a cluster within AWS, it would lower the necessity to move providers. The initial tests we did with kops looked promising and we decided to take it a step further. It’s time to set up a High Availability cluster.
To understand what HA means for Kubernetes, we need to first understand what it means in general.
The central foundation of a highly available solution is a redundant, reliable storage layer. The number one rule of high-availability is to protect the data. Whatever else happens, whatever catches on fire, if you have the data, you can rebuild. If you lose the data, you’re done.
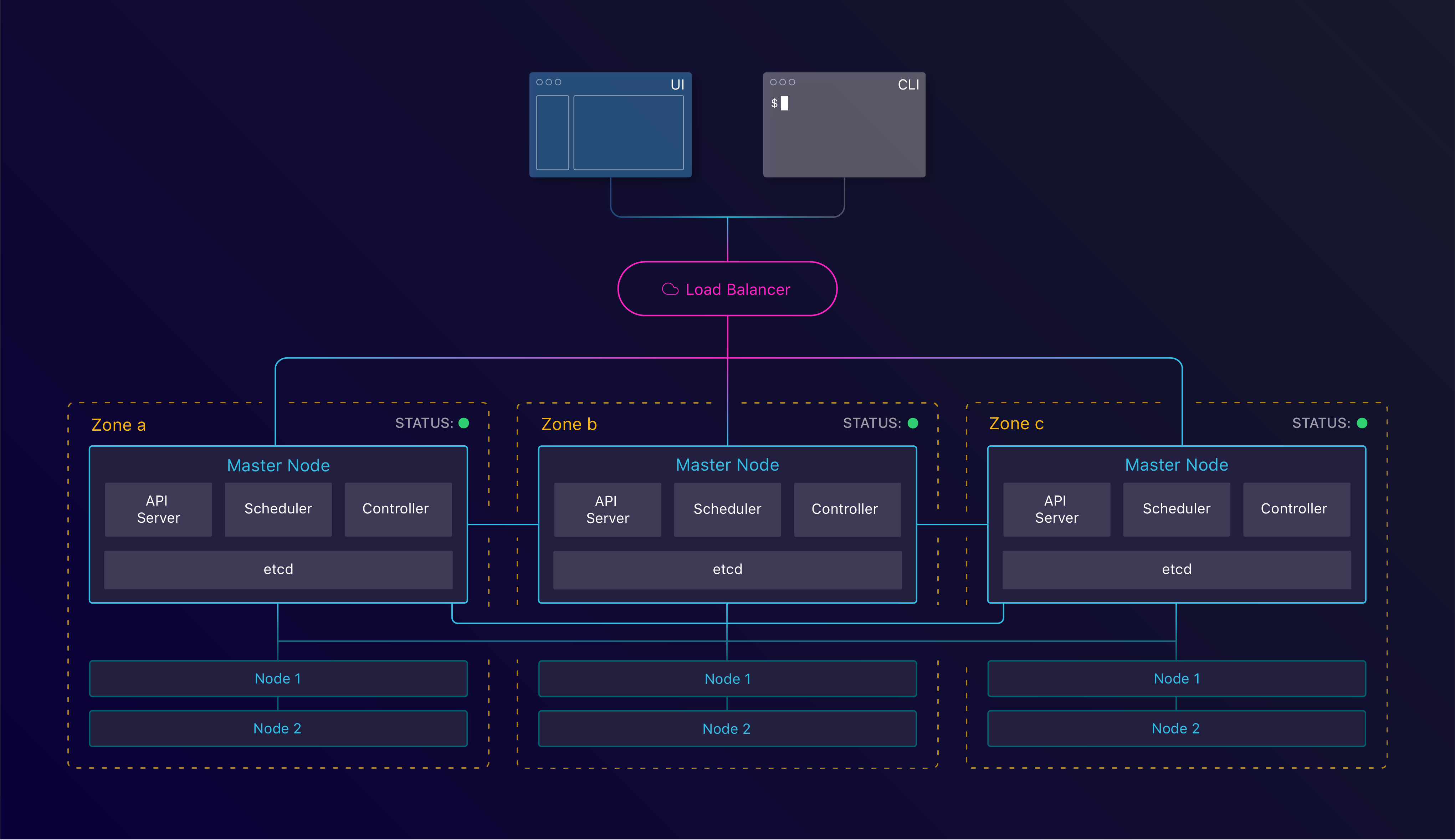 Kubernetes components in a High Availability configuration
Kubernetes components in a High Availability configuration
Within a Kubernetes cluster, this storage layer is etcd and runs on the master instances. etcd is a distributed key/value store which follows the Raft consensus algorithm to achieve quorum. Achieving quorum means having a set of servers agreeing on a set of values. To reach this consensus, it needs lower(n/2)+1 parties to agree. Therefore we always need an uneven amount of instances with at least 3.
Below, we’ll look at a few possible disruption cases.
Tolerating instance failure
The first scenario we’ll look at is to see what happens when a single instance terminates. Can we recover from this?
 Tolerating instance failure
Tolerating instance failure
By specifying the amount of nodes we want, kops creates an Auto Scaling Group per instance group. This ensures that when an instance terminates, a new one gets created. This allows us to keep consensus across our cluster when we lose an instance.
Tolerating zone failure
Having set up instance failure allows us to tolerate failure of a single machine. But what happens when the whole datacenter is having issues due to a power cut for example? This is where Regions and *Availability Zones* come into play.
Let’s look back at our consensus formula: lower(n/2)+1 instances with at least 3 instances. We can translate this to zones, which would result in lower(n/2)+1 zones with at least 3 zones.
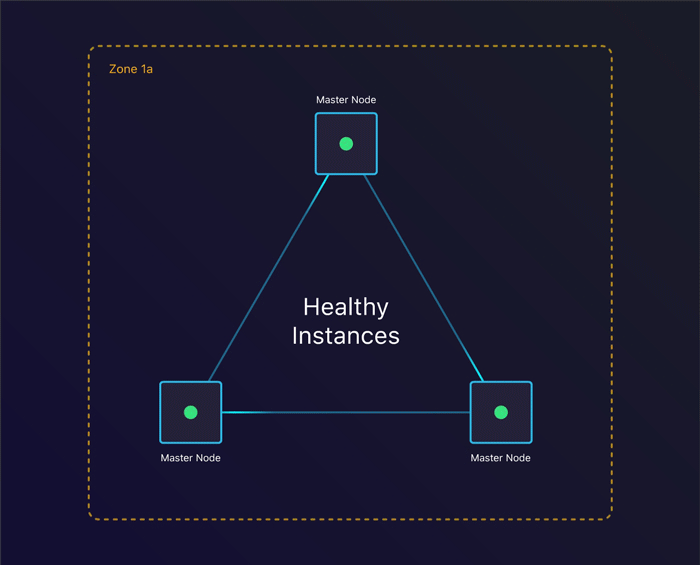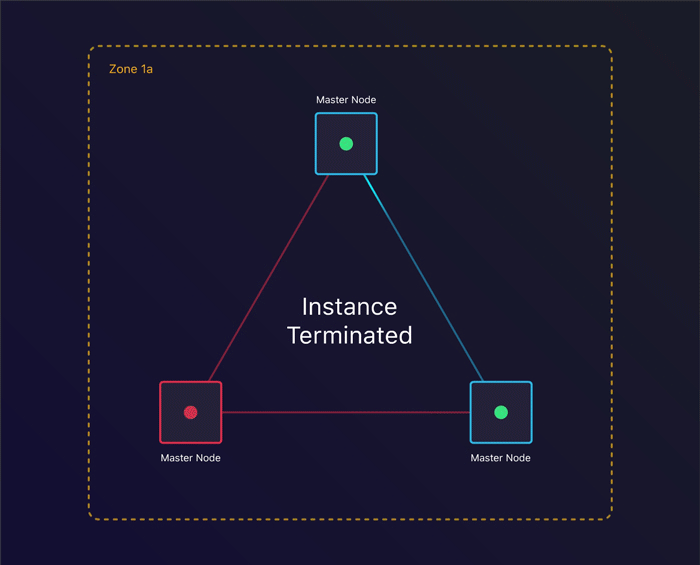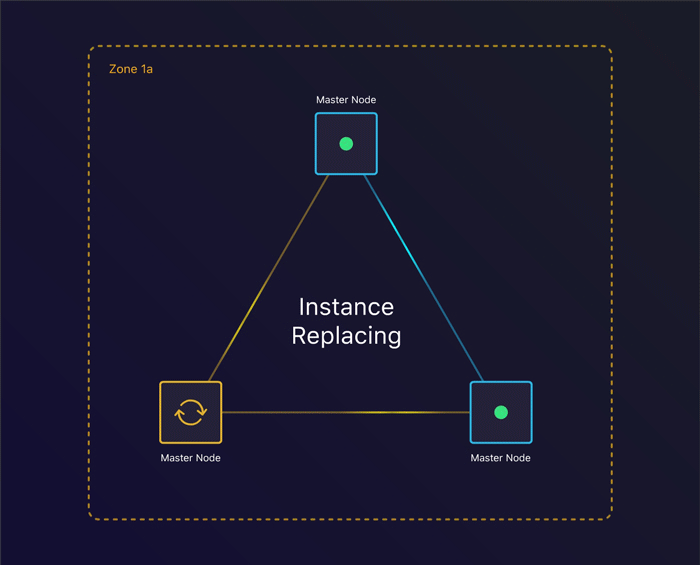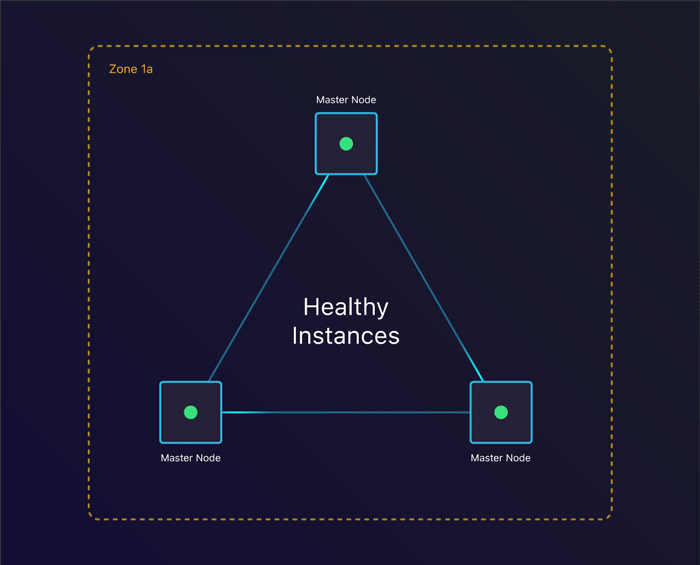
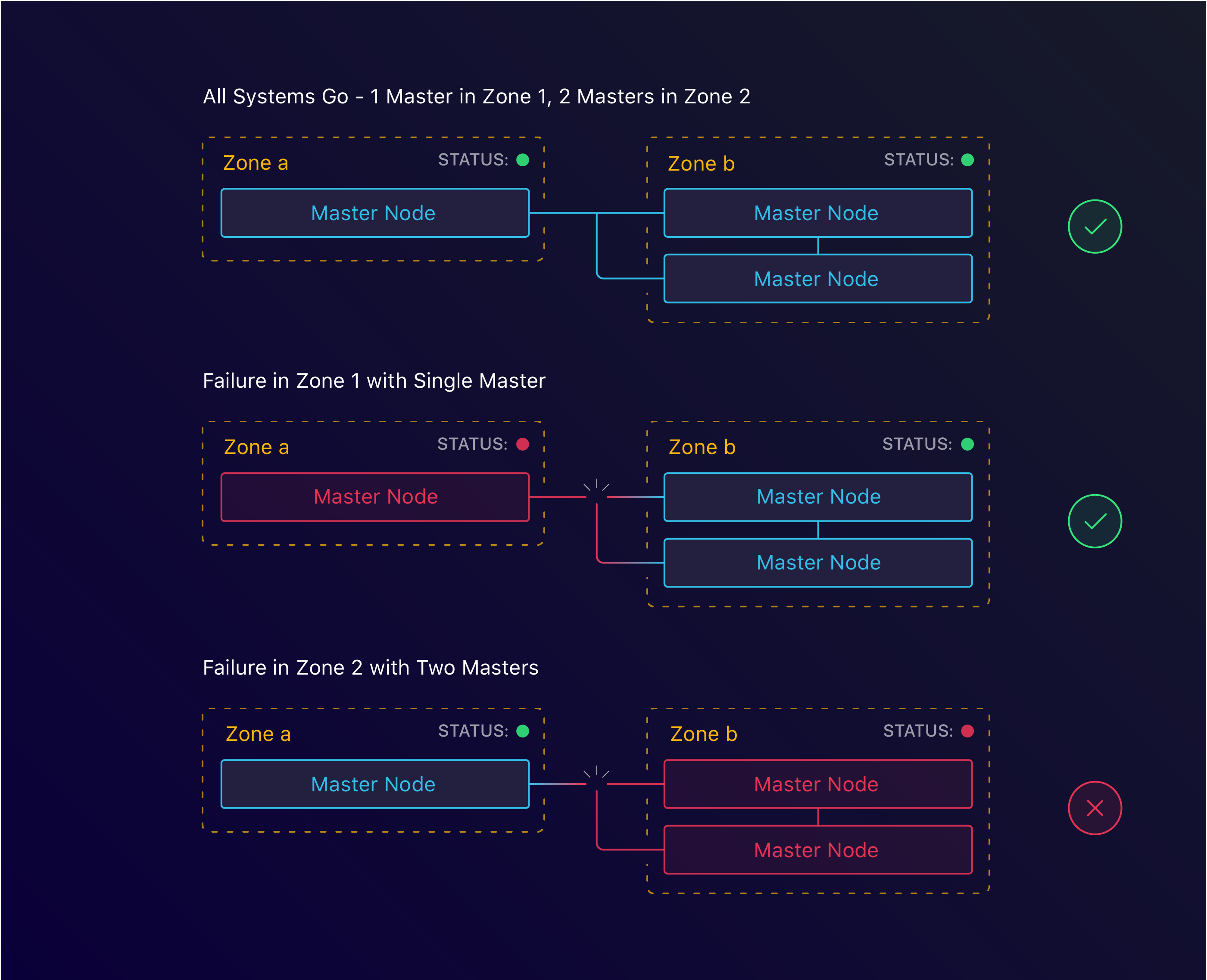 3 master nodes spread across 2 zones
3 master nodes spread across 2 zones
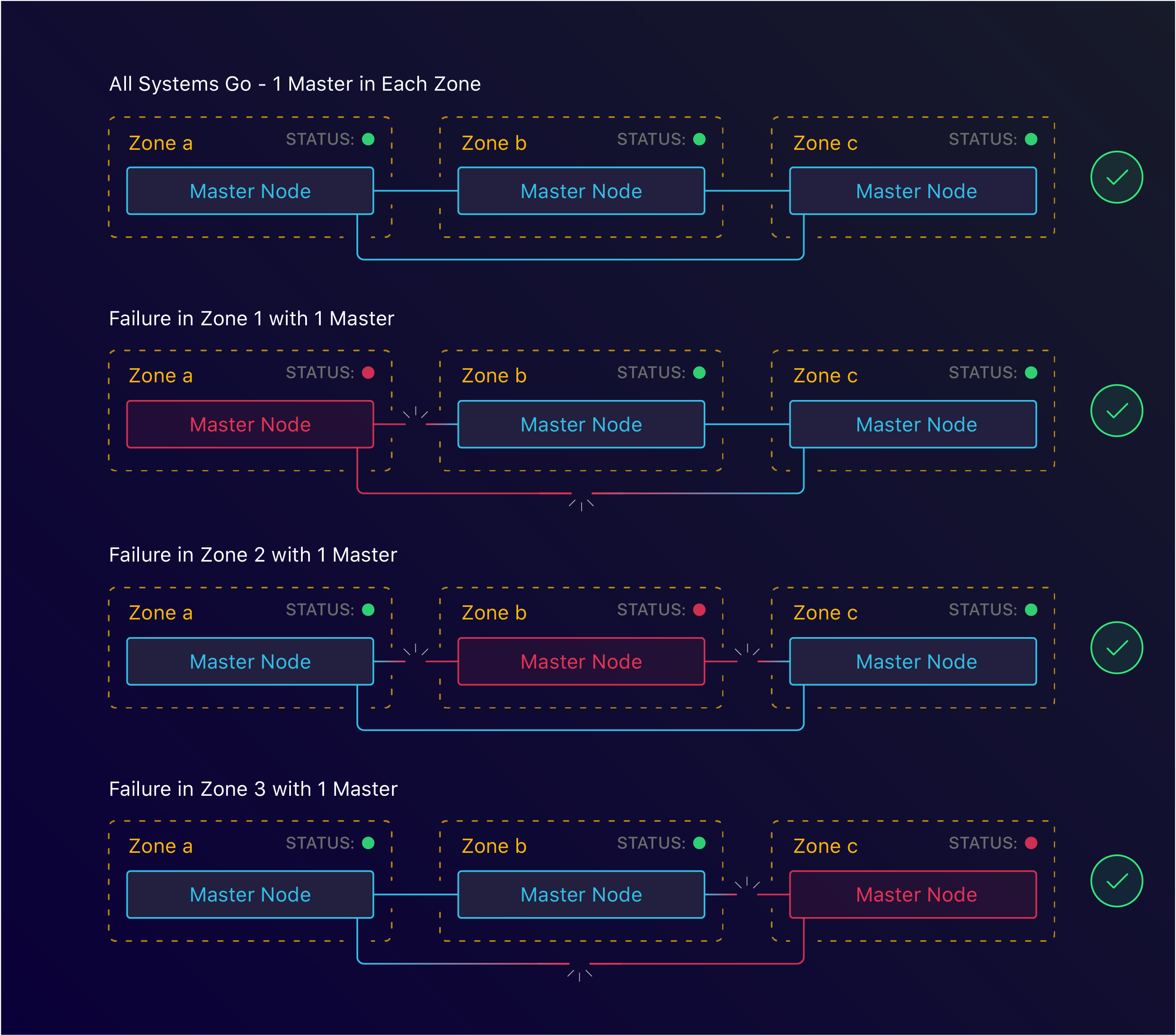 3 master nodes spread across 3 zones
3 master nodes spread across 3 zones
With kops, this too is simple. By specifying the zones we want to run both our masters and nodes in, we can configure HA at the zone level. This however is where we ran into our first roadblock. For arbitrary reasons, when we started Manifold, we decided to use the us-west-1 region. As it turns out, this region only has 2 zones available. This meant that we’d have to find another solution to tolerate zone failure.
Tolerating region failure (and beyond)
The main goal was to replicate the existing infrastructure. Our legacy setup did not run across multiple regions, so the new setup didn’t have to either. We do believe that with the help of Kubernetes Federation, this will be easier to set up.
Internal Networking with Peering
Because of our regional restrictions, we had to find other ways to tolerate zone failure. One option is to create our cluster in a separate region.
Each region runs its own separated network. This means that we can’t just use resources from one region in the other. For this, we looked into inter-region VPC peering. This would allow us to connect to our us-west-1 region and access RDS and KMS.
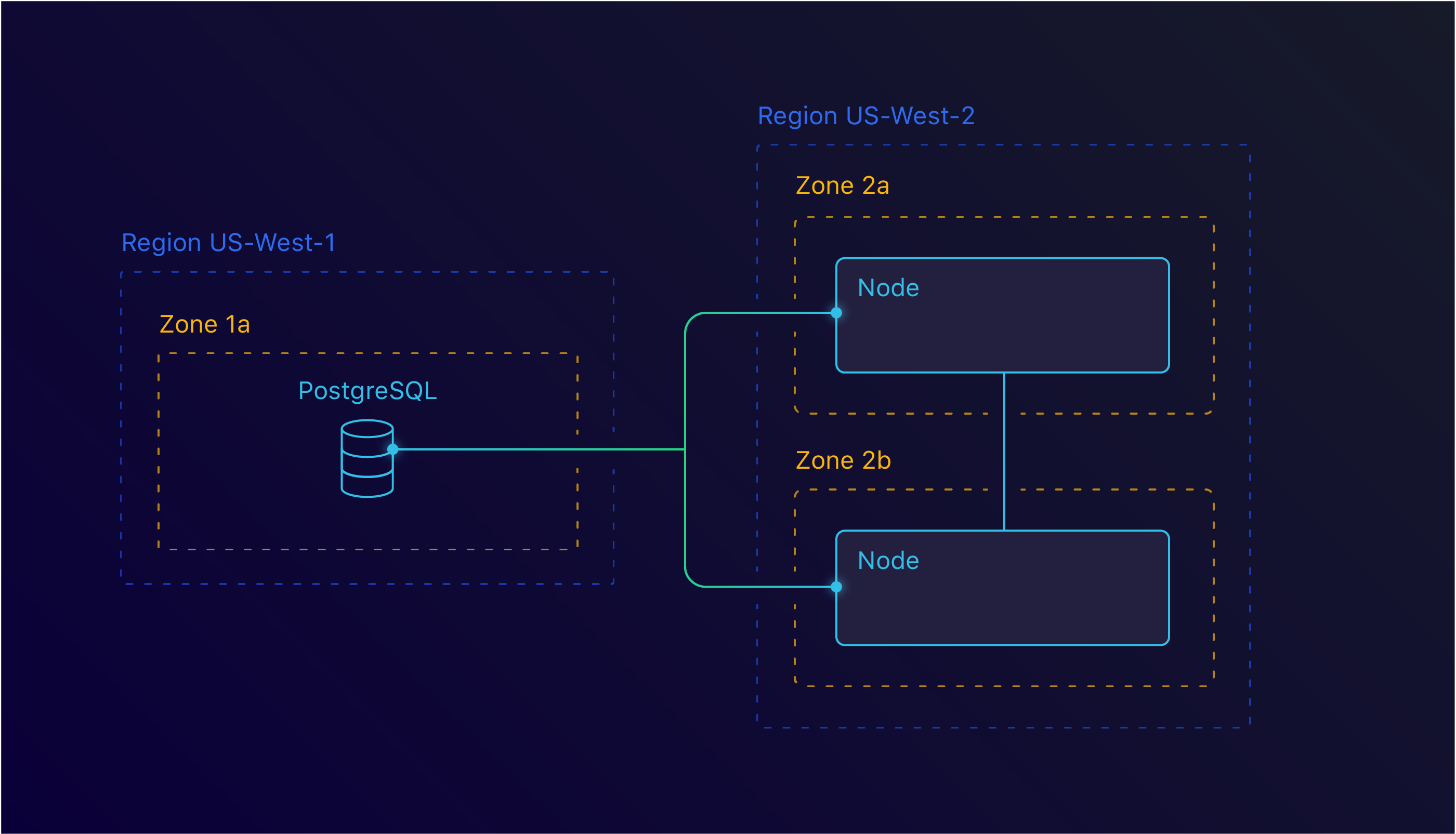 Inter Region peering between us-west-1 and us-west-2
Inter Region peering between us-west-1 and us-west-2
This too set us back. As it turns out, the us-west-1 region isn’t the best region you could use. At the time we investigated this, us-west-1 didn’t support inter-region VPC peering. This means that we couldn’t use this solution either.
Decisions and compromises
With all this new knowledge, it was time to make a decision. Would we stay with AWS or move over to another provider?
It’s worth noting that moving to another provider comes with a lot of extra overhead as well. We’d have to expose our database, migrate our KMS and re-encrypt all our data.
In the end, we decided to stick with AWS and run with the tolerating node failure solution. With the announcement of Amazon EKS and inter-region peering coming soon, we felt like this was a good enough first step.
Managing your own cluster can be time consuming. To date, we’ve seen minimal impact, but we definitely accounted for cluster maintenance. The most time consuming would be cluster updates.
From a financial standpoint, we also compromised. Yes, it’d be cheaper than the legacy setup, but it’d be more expensive than the competitors. Azure and GCP both provide the master nodes for free, which cuts down in cost quite a bit.
kops tips
For us, kops has worked great. It does come with a set of defaults that you should be aware of and overwrite. One of the key things to do is to enable etcd encryption. This is done by providing the* — encrypt-etcd-storage* flag.
By default, kops also doesn’t enable RBAC. RBAC is a great mechanism to limit the scope of your applications within your cluster. We highly recommend enabling this and setting up appropriate roles.
For security reasons, we’ve disabled SSH into our instances. This ensures that no one can access these boxes, even when we run with a private network topology.
Configuring the cluster
With a cluster up and running, it’s time to get to work. The next step would be to configure it so that we can start deploying applications into it.
Having managed our services with Terraform before meant that we had quite a bit of control on how to set things up. We managed our ELBs, DNS, logging etc. through our Terraform configuration. We needed to make sure we can do this with our Kubernetes setup as well.
Load Balancing
Kubernetes has the notion of Services and Ingresses. With a Service, it’s possible to group pods — usually managed by a Deployment — and expose them under the same endpoint. This endpoint could either be internal or external. When configuring a Service as a LoadBalancer, Kubernetes will generate an ELB. This ELB is then linked to the configured service.
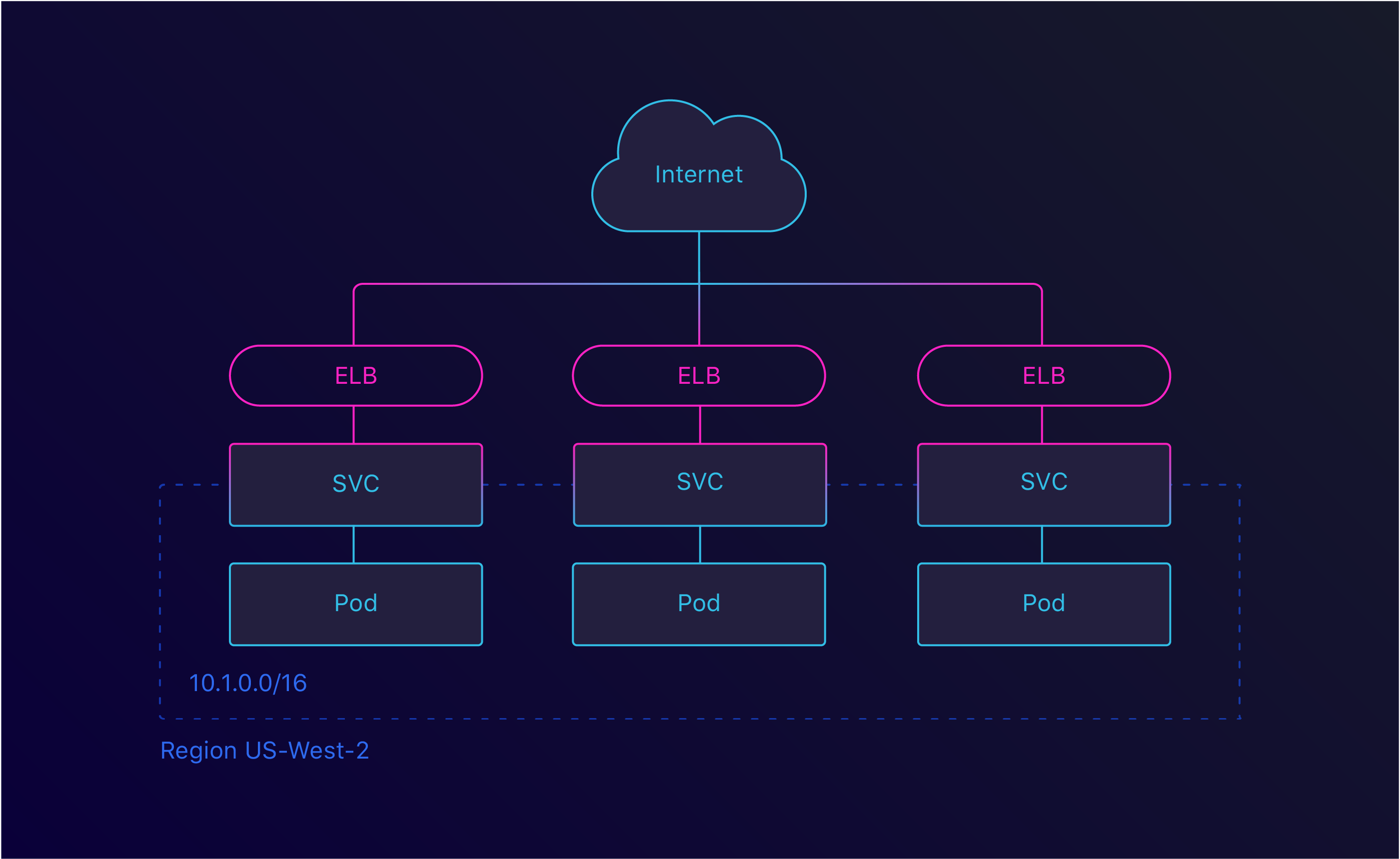 Service LoadBalancer
Service LoadBalancer
This is great, but there are limits on the amount of ELBs you can have. By using an Ingress, we can create a single ELB and route the traffic within our cluster. There are several Ingresses available, but we went with the default Nginx Ingress.
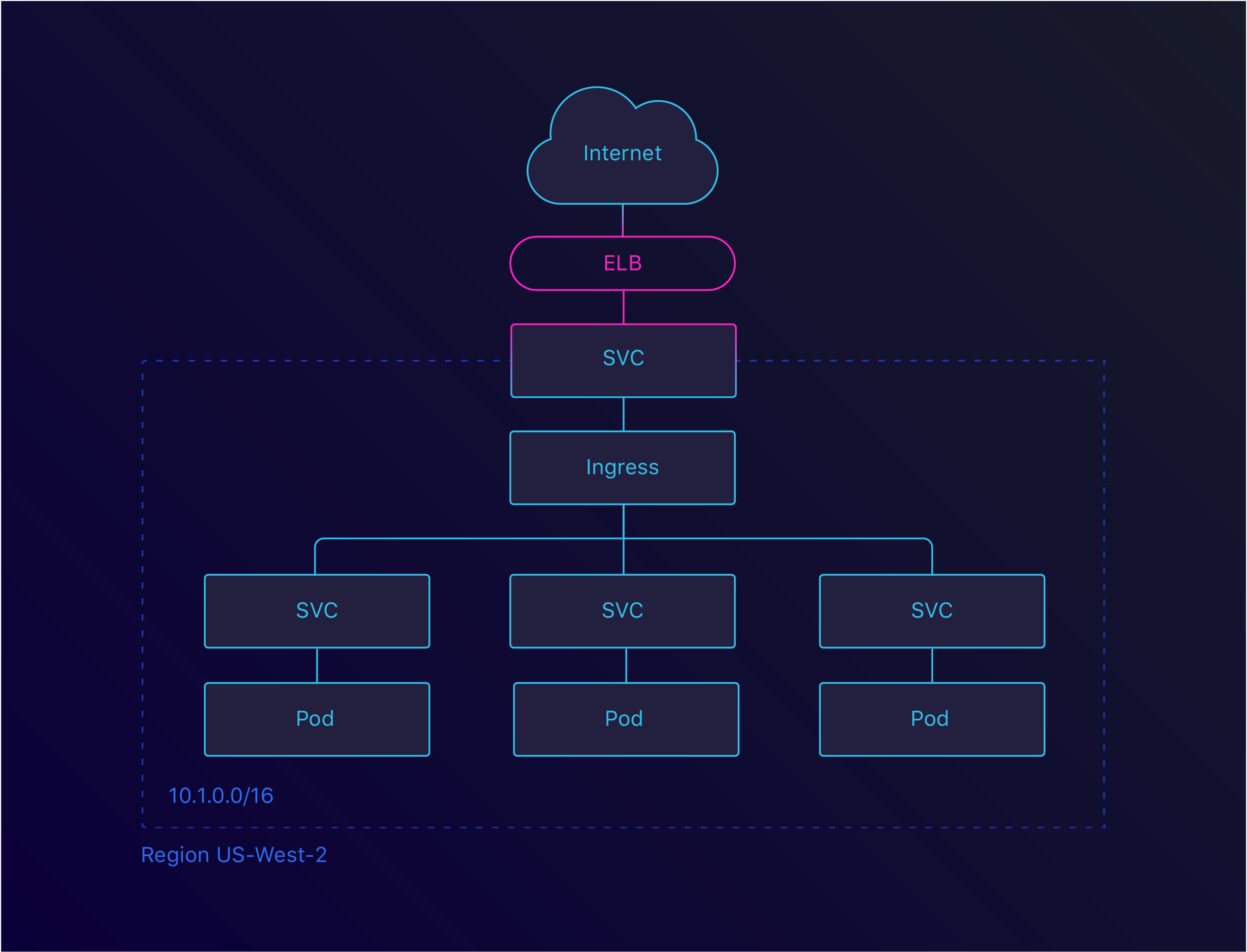 Ingress LoadBalancer
Ingress LoadBalancer
Now that we can route traffic to a service, it’s time to expose these through a domain. To do this, we used the External DNS project. This is a great way to keep the configured domain names close to your application.
The last step we had to look at for exposing our services was making sure we served traffic through SSL. This turned out to be easy as well as there are already available solutions to this. We settled on cert-manager, which integrates with our Nginx Ingress.
Service Configuration
Service Configuration was an easy win for us. We already started building Manifold on top of Manifold with our Terraform Integration. Because of this, all the credentials we needed were already configured.
We designed our Kubernetes Integration with our Terraform Integration in mind. We kept the underlying semantics the same which meant that migrating credentials was a breeze.
We also added the option for custom secret types. This allowed us to configure a Docker Auth secret. When pulling Docker images from a private registry, you need this secret.
Telemetry
One of the most important things of running a distributed system is knowing what’s going on inside of it. For this, you need to set up centralized logging and metrics. We had this in our legacy platform so we definitely needed this in our new platform.
For logging, we expanded our dogfooding and set up our LogDNA Integration to gather logs. LogDNA themselves provide a DaemonSet configuration. This allows you to ship the logs from your cluster to their platform.
For metrics, we were relying on Datadog which worked well for us so far. As with LogDNA, Datadog also provides a DaemonSet configuration. They even have a great blog post on how to set this up!
Migration
With the cluster configured and our applications deployed, it was time to migrate. To ensure zero down time, we had to do this in several stages.
The first stage was running the cluster on a** separate domain**. By connecting the two systems, we could test it without interrupting anyone. This helped us find and fix some early stage issues.
In the next stage, we’d route some traffic to the Kubernetes cluster. To do this, we set up round robin. This is a great way to see how your cluster behaves with actual traffic. After about a week, we had enough confidence to move on to the next phase.
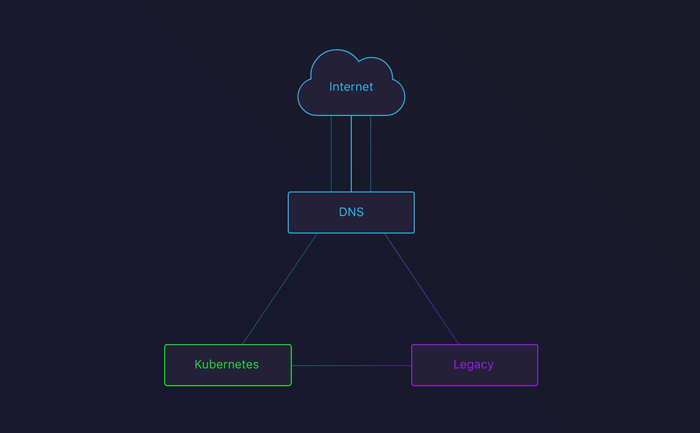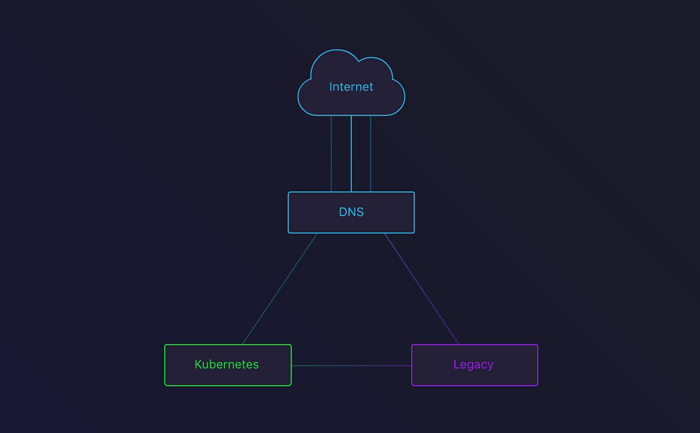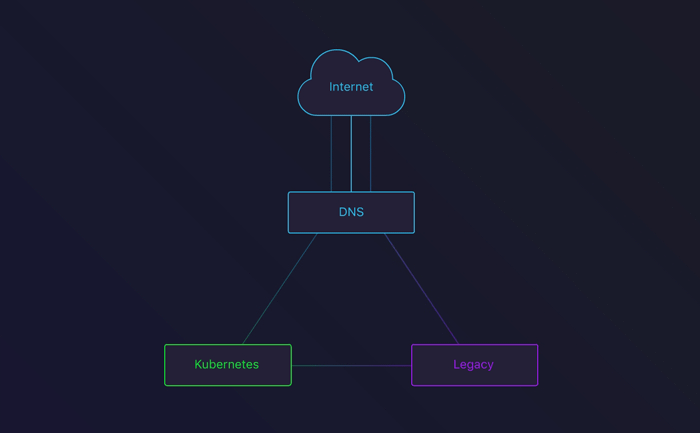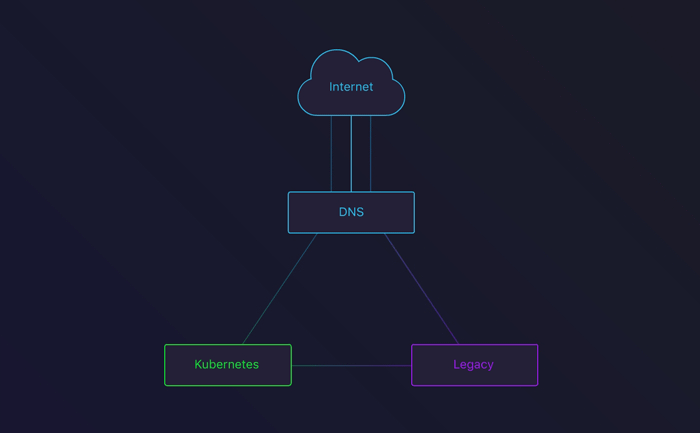 DNS round-robin between the Legacy infrastructure and our Kubernetes cluster
DNS round-robin between the Legacy infrastructure and our Kubernetes cluster
The third stage involved removing the legacy DNS records. After removing the appropriate Terraform configuration, all our traffic would flow through Kubernetes!
Because of DNS cache, we decided to keep the legacy up and running for a few more days. This way, people with a cached DNS entry would not encounter an error. This also gave us the possibility to rollback in case we saw something go wrong.
Conclusion
Now that we’ve migrated, we can reflect back on things. Our team — and the company — has called this migration a success. We decreased our deployment time from ~15min to ~1.5min and managed to cut operational costs by doing so.
We still haven’t finished up our Continuous Delivery pipeline, but we’re working on it. We’ve started work on Heighliner which will in the first place help ourselves, but hopefully help others as well.
We encountered one major setback: not having 3 availability zones available to us. This prevented us from running Highly Available across zones. It’s a compromise we decided to make to get us up and running and we’ll be looking at fixing that soon.
Oh, and one more thing. So. Much. YAML. This is where Heighliner will help us out.
Massive shout-out to Meg Smith for her work on the images for this blog post.